目录
概述
环境依赖
数据描述
代码概述
导包
数据读取
统计缺失值
数据结构概述
描述统计
时间轴数据转换
月交易统计直方图
周交易统计图
小时数据转换
小时折线图
销售关系可视化统计
销售占比扇形图
价格箱线图
各类别多维度条形图统计
商店位置交易量折线图
不同位置产品受欢迎统计量
总收入统计
总结
配套源码和数据
配套源码和数据
概述
在这个Kaggle的笔记本中,作者进行了关于咖啡店销售数据的分析。该案例提供了对数据科学和可视化技巧的全面展示,适合用作博客内容来介绍如何用Python分析实际商业数据。这个Kaggle笔记本是一个很好的例子,展示了如何利用数据科学技术来分析和解释商业数据,适合在博客中介绍数据科学在现实世界中的应用。你可以在博客中详细介绍每个步骤的技术细节和业务洞察,为读者提供实际操作的框架和灵感。
环境依赖
-
编程语言:
- Python:作为数据科学领域最受欢迎的编程语言之一,Python 提供了丰富的库和框架,适合进行数据处理、分析、机器学习和可视化等任务。
-
主要的库和工具:
- NumPy:提供高性能的多维数组对象和对这些数组的操作。它是进行科学计算的基础库,支持大量的维度数组和矩阵运算。
- Pandas:提供了DataFrame等数据结构,支持灵活的数据操作,是处理结构化数据的理想工具。
- Matplotlib:一个强大的绘图库,支持多种静态、动态和交互式的图表。
- Seaborn:基于Matplotlib,集成了更多的图表类型,专注于统计可视化,使用简单的代码就可以生成复杂的统计图表。
- Plotly:支持创建交互式图表的库,使得数据的展示更加直观和互动。
-
开发环境:
- Jupyter Notebook 或 JupyterLab:这是数据科学领域广泛使用的开发工具,提供了一个便捷的web界面,允许你创建和共享包含实时代码、可视化和说明文本的文档。
- IDEs(如 PyCharm, Visual Studio Code):这些集成开发环境支持更复杂的项目管理和开发需求,提供代码编辑、调试和版本控制等功能。
-
安装和管理工具:
- pip:Python的包安装器,用于安装和管理上述库。
- conda:一个开源包管理系统和环境管理系统,可以用于安装、运行和升级包和依赖关系。
-
操作系统:
- 可以在多种操作系统上部署,如Windows、macOS和Linux等,这些系统提供了运行Python及其库的平台。
数据描述
| 字段名称 | 描述 |
|---|---|
| transaction_id | 代表单个交易的唯一顺序ID。 |
| transaction_date | 交易日期(格式:MM/DD/YY)。 |
| transaction_time | 交易时间戳(格式:HH:MM:SS)。 |
| transaction_qty | 销售商品的数量。 |
| store_id | 发生交易的咖啡店的唯一ID。 |
| store_location | 发生交易的咖啡店的位置。 |
| product_id | 销售产品的唯一ID。 |
| unit_price | 销售产品的零售价格。 |
| product_category | 产品类别的描述。 |
| product_type | 产品类型的描述。 |
| product_detail | 产品详细描述。 |
代码概述
导包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
from plotly.offline import iplot
from plotly.subplots import make_subplots这段代码是用于导入进行数据分析和可视化所需的Python库的标准代码。各个库的功能和用途如下:
-
numpy (np): 提供了支持大量维度数组与矩阵运算的函数库,是科学计算的基础包。广泛用于数据处理中的各种数学运算。
-
pandas (pd): 是Python的一个数据分析库,提供了高效地操作大型数据集所需的工具和数据结构,如DataFrame。
-
matplotlib.pyplot (plt): 是一个非常流行的绘图库,提供了一种类似于MATLAB的绘图系统。用于创建静态、动态、交互式的图表。
-
seaborn (sns): 基于matplotlib的数据可视化库,提供了一种高级接口,专注于统计图形的绘制。它使得绘制吸引人的统计图表变得更简单。
-
plotly.express (px) 和 plotly.subplots:
- plotly.express: 是一个简化的接口,允许快速制作复杂的图表。Plotly Express 支持一系列图表和图形类型。
- make_subplots 和 iplot:用于创建多子图(subplot)的布局和交互式图表。make_subplots 用于构建含有多个子图的图表布局,而 iplot 是用于显示交互式图表的函数。
这些库共同为数据科学和机器学习项目提供了强大的数据探索、处理、分析及可视化能力。使用这些工具,你可以从大量数据中洞察见解并以图形的方式展示出来,非常适合进行复杂的数据分析和生成专业的报告。
数据读取
df = pd.read_excel('Coffee Shop Sales.xlsx')
df.head()-
加载 Excel 文件:
pd.read_excel('Coffee Shop Sales.xlsx'):这是 Pandas 库用来读取 Excel 文件的函数。它接受文件名作为参数,将数据加载到 DataFrame 中。这是直接处理 Excel 文件的高效方法。
-
查看数据:
df.head():此函数默认返回 DataFrame 的前五行。这是一种快速查看数据初貌的方法,可以帮助你了解数据集包含哪些列和基本的数据格式。
统计缺失值
print(df.isna().sum())
print(df.isnull().sum())
print(df.isnull().sum())数据结构概述
print(df.info())
#################################################
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 149116 entries, 0 to 149115
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 transaction_id 149116 non-null int64
1 transaction_date 149116 non-null datetime64[ns]
2 transaction_time 149116 non-null object
3 transaction_qty 149116 non-null int64
4 store_id 149116 non-null int64
5 store_location 149116 non-null object
6 product_id 149116 non-null int64
7 unit_price 149116 non-null float64
8 product_category 149116 non-null object
9 product_type 149116 non-null object
10 product_detail 149116 non-null object
dtypes: datetime64[ns](1), float64(1), int64(4), object(5)
memory usage: 12.5+ MB这段代码 df.info() 用于展示 Pandas DataFrame df 中的信息概览。它显示了数据框的每一列的名称、非空值的数量、数据类型以及内存的使用情况。下面是对这段输出的详细中文解释:
-
DataFrame 结构:该 DataFrame 共包含 149116 条记录,从索引 0 到 149115。
-
列总数:数据集总共有 11 个列。
-
列的详情:
- transaction_id:交易ID,149116 个非空值,数据类型为整数(int64)。
- transaction_date:交易日期,149116 个非空值,数据类型为日期时间(datetime64[ns])。
- transaction_time:交易时间,149116 个非空值,数据类型为字符串(object)。
- transaction_qty:交易数量,149116 个非空值,数据类型为整数(int64)。
- store_id:商店ID,149116 个非空值,数据类型为整数(int64)。
- store_location:商店位置,149116 个非空值,数据类型为字符串(object)。
- product_id:产品ID,149116 个非空值,数据类型为整数(int64)。
- unit_price:单价,149116 个非空值,数据类型为浮点数(float64)。
- product_category:产品类别,149116 个非空值,数据类型为字符串(object)。
- product_type:产品类型,149116 个非空值,数据类型为字符串(object)。
- product_detail:产品详情,149116 个非空值,数据类型为字符串(object)。
-
内存使用:大约为 12.5 MB。
描述统计
# describing the numerical data
df.describe()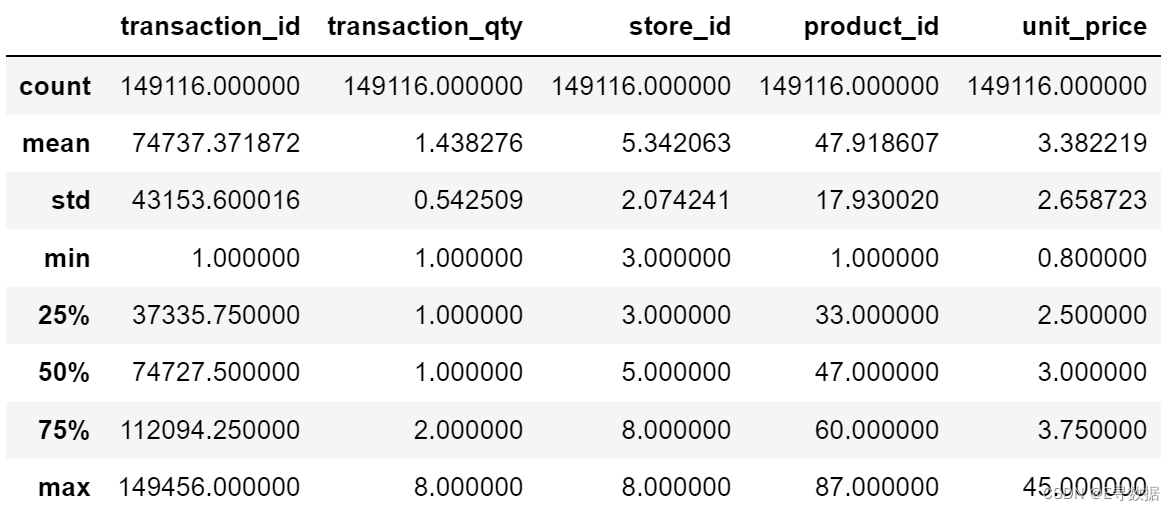
# describing the categorical data
df.describe(include= object)
时间轴数据转换
# add new column year
df["year"] = df["transaction_date"].dt.year
# add new column month
df["month"] = df["transaction_date"].dt.month_name()
# add new column day
df["day"] = df["transaction_date"].dt.day_name()这段代码是在 df DataFrame 中基于 transaction_date 列添加三个新的时间维度列:年份(year)、月份名称(month)和星期名称(day)。每个新列都是从原始的日期时间列 transaction_date 派生而来,具体功能如下:
-
添加年份列:
df["year"] = df["transaction_date"].dt.year:通过访问日期时间列的.dt属性和.year属性,将交易日期的年份提取出来,并创建一个名为year的新列。
-
添加月份名称列:
df["month"] = df["transaction_date"].dt.month_name():同样通过.dt属性,使用.month_name()方法获取月份的英文名称(如 "January", "February" 等),并将其存储在名为month的新列中。
-
添加星期名称列:
df["day"] = df["transaction_date"].dt.day_name():使用.day_name()方法从日期中提取出星期的名称(如 "Monday", "Tuesday" 等),并将这些信息保存在名为day的新列中。
月交易统计直方图
iplot(px.bar(x=transactions_per_month.index, y=transactions_per_month.values,
labels={'x': 'Month', 'y': 'Number of Transactions'},
title='Transactions per Month', text_auto= True))
代码使用了 Plotly 的 px.bar 函数来创建一个条形图,该图显示了每个月的交易数量。这是一个交互式可视化,使用 iplot 函数来显示图表。
-
px.bar:这是 Plotly Express 库中的一个函数,用于创建条形图。它接收几个参数:
- x:x轴的数据,这里是
transactions_per_month.index,通常代表月份。 - y:y轴的数据,这里是
transactions_per_month.values,表示每个月的交易次数。 - labels:一个字典,用于自定义 x轴和 y轴的标签。这里将 x轴标签设为“Month”(月份),y轴标签设为“Number of Transactions”(交易数量)。
- title:图表的标题,“Transactions per Month”(每月交易量)。
- text_auto:自动在条形图的每个条上显示数值。
- x:x轴的数据,这里是
-
iplot:这是 Plotly 库的函数,用于显示图表。在 Jupyter Notebook 或其他支持的环境中,它会生成一个交互式图表,允许用户通过鼠标悬停、放大、缩小等操作来更详细地查看数据。
# Same plot using seaborn
plt.figure(figsize=(10, 6))
sns.barplot(x=transactions_per_month.index, y=transactions_per_month.values, color='skyblue', palette = "RdBu")
plt.title('Transactions per Month')
plt.xlabel('Month')
plt.ylabel('Number of Transactions')
plt.show()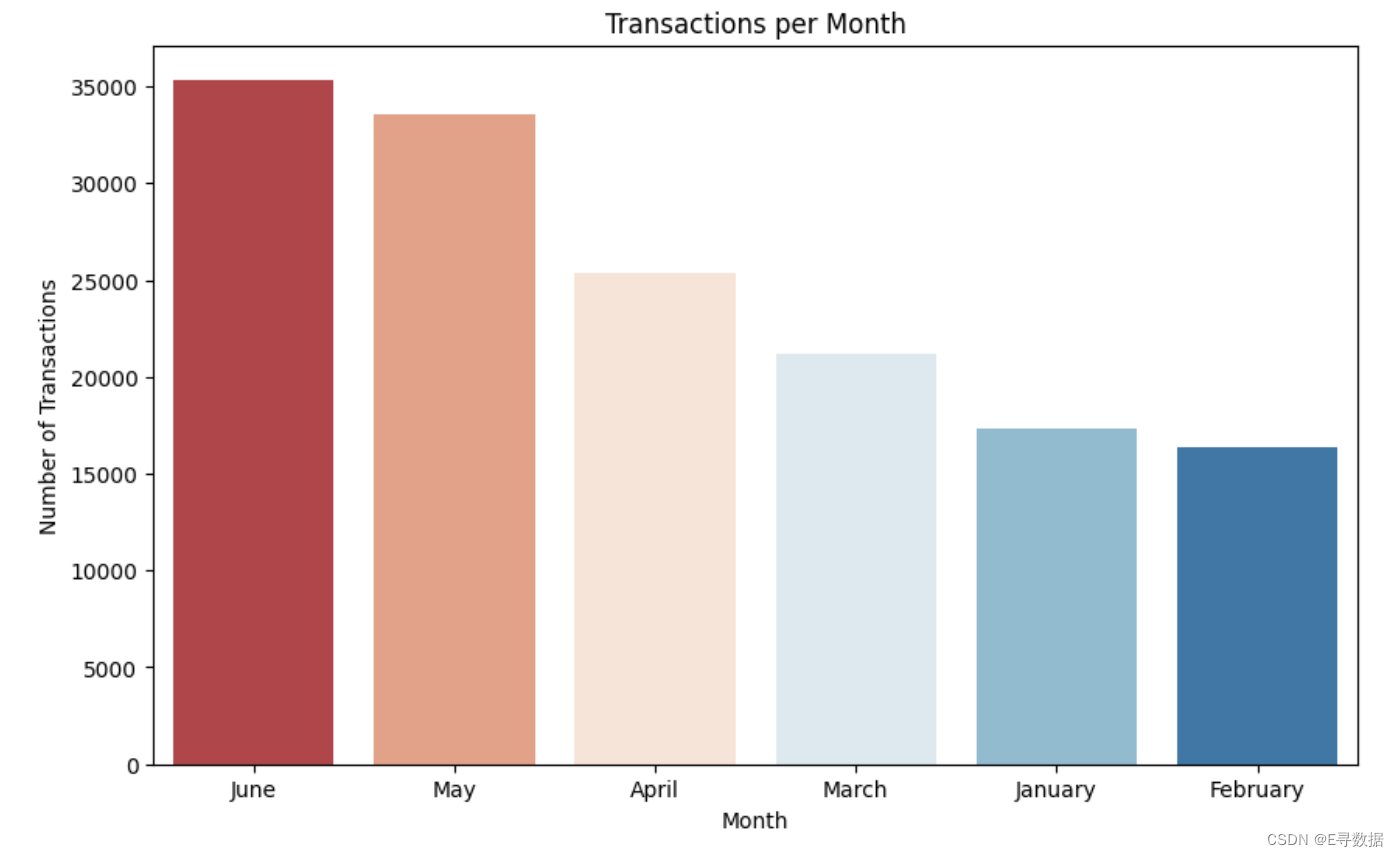
这段代码使用了 Seaborn 库来创建一个条形图,显示每个月的交易数量。与前面使用 Plotly Express 的方法相比,Seaborn 提供了一个更静态的可视化方式,但它在学术和专业报告中非常受欢迎,因为其美观和易于生成的高质量图形。下面是代码详细解释:
-
plt.figure:这是 Matplotlib 库的一个函数,用于创建一个新的图形窗口。这里设置图形的大小为 10x6 英寸。
-
sns.barplot:这是 Seaborn 库的函数,用于绘制条形图。它的参数包括:
- x:x轴的数据,这里是
transactions_per_month.index,通常表示月份。 - y:y轴的数据,这里是
transactions_per_month.values,表示每个月的交易数量。 - color:设置条形的颜色,这里选用的是 'skyblue'。
- palette:颜色主题,这里使用的是 "RdBu",它是从红到蓝的渐变色,通常用于强调数据的高低或正负变化。
- x:x轴的数据,这里是
-
plt.title, plt.xlabel, plt.ylabel:这些 Matplotlib 函数用于设置图形的标题和坐标轴标签。
-
plt.show:这个函数用于显示整个图形。在 Jupyter Notebook 中,这会导致图形在输出单元中显示。
周交易统计图
iplot(px.bar(x=transactions_per_day.index, y=transactions_per_day.values,
labels={'x': 'Month', 'y': 'Number of Transactions'},
title='Transactions per Day', text_auto= True))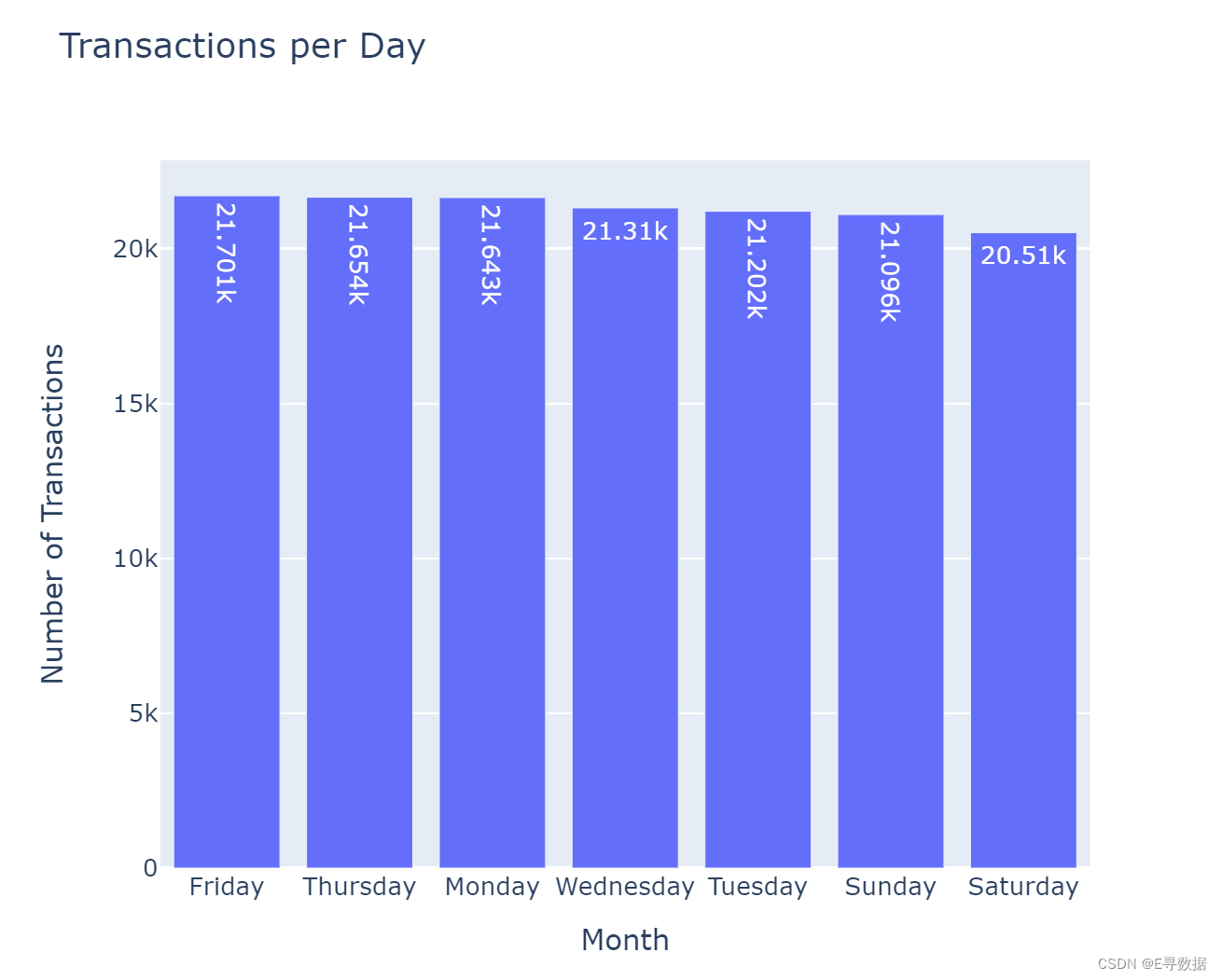
这段代码使用了 Plotly Express 库的 px.bar 函数来创建一个每日交易量的条形图。这是一种交互式可视化,可以通过 iplot 函数直接在支持的环境(如 Jupyter Notebook)中显示。以下是代码的详细说明:
-
px.bar:Plotly Express 的条形图绘制函数,接收的参数如下:
- x:x轴数据,这里是
transactions_per_day.index,通常表示每天的日期。 - y:y轴数据,这里是
transactions_per_day.values,表示每天的交易数量。 - labels:定义 x 轴和 y 轴的标签,这里的 x 轴标签误标为 'Month',应改为 'Day'。
- title:图表的标题,这里是 "Transactions per Day"(每日交易量)。
- text_auto:自动在每个条形上显示数值,使得每个条形的具体数值一目了然。
- x:x轴数据,这里是
-
iplot:用于显示图表的 Plotly 函数。它生成的是交互式图表,使得用户可以通过鼠标悬停、缩放等操作详细查看图表数据。
# Same plot using seaborn
plt.figure(figsize=(10, 6))
sns.barplot(x=transactions_per_day.index, y=transactions_per_day.values, color='skyblue', palette = "RdBu")
plt.title('Transactions per Day')
plt.xlabel('Month')
plt.ylabel('Number of Transactions')
plt.show()
这段代码使用 Seaborn 库来创建一个显示每天交易量的条形图。与 Plotly 的交互式图表相比,Seaborn 提供的是静态图表,但同样清晰美观,适用于打印或展示在报告中。下面是代码的详细解释:
-
plt.figure:设置图表的尺寸为10英寸宽和6英寸高。
-
sns.barplot:这是一个用于生成条形图的 Seaborn 函数,其参数如下:
- x:x轴数据,此处为
transactions_per_day.index,表示日期。 - y:y轴数据,此处为
transactions_per_day.values,表示每天的交易数量。 - color:设置条形的颜色为 'skyblue'。
- palette:颜色主题,这里使用 "RdBu",它是红蓝渐变色,用于表示数据的变化强度或范围。
- x:x轴数据,此处为
-
plt.title, plt.xlabel, plt.ylabel:设置图表的标题、x轴和y轴标签。注意,这里的
plt.xlabel应标记为 'Day' 而非 'Month',以正确反映数据的时间维度。 -
plt.show:这个函数用于在 Python 脚本或 Jupyter Notebook 中显示生成的图形。
小时数据转换
# add new column hour
df["hour"] = df["transaction_time"].apply(lambda x : x.hour)
df.head()-
添加小时列:
df["hour"] = df['transaction_time'].apply(lambda x: x.hour)通过一个 lambda 函数提取时间对象的小时部分。这里假设transaction_time列已经是时间对象,因此可以直接调用.hour属性。
-
查看结果:
df.head()显示 DataFrame 的前五行,以验证新列hour是否已正确添加。
小时折线图
# see distribution
sns.kdeplot(df["hour"])
plt.title('Most Sales per each hour')
plt.show()这段代码使用了 Seaborn 的 sns.kdeplot 函数来绘制 hour 列的核密度估计(KDE)图,这是一种用于展示变量分布的图表,特别适用于显示销售在一天中各个小时的分布情况。以下是代码的详细解释:
-
sns.kdeplot(df["hour"]):这个函数调用绘制了
hour数据的核密度估计图。核密度估计是一种平滑的概率密度函数,能够清晰地展示数据点在各个值上的分布密度。 -
plt.title('Most Sales per each hour'):设置图表的标题,这里描述的是“每个小时的最多销售量”,意在展示一天中哪些小时是销售高峰。
-
plt.show():此函数调用确保了图表能够在 Python 脚本或 Jupyter Notebook 中被渲染并显示出来。
销售关系可视化统计
iplot(px.bar(x=no_sales_quantity.index, y=no_sales_quantity.values,
labels={'x': 'Quantity', 'y': 'Number of sales'},
title='Number of sales quantity', text_auto= True))-
px.bar:Plotly Express 中用于生成条形图的函数,它接受以下参数:
- x:x轴的数据,这里是
no_sales_quantity.index,通常代表销售数量的不同类别或分组。 - y:y轴的数据,这里是
no_sales_quantity.values,表示每个销售数量对应的销售次数。 - labels:一个字典,用于定义x轴和y轴的标签,这里的x轴标签设为 'Quantity'(数量),y轴标签设为 'Number of sales'(销售次数)。
- title:图表的标题,这里设为 'Number of sales quantity'。
- text_auto:自动在条形上显示数值,这使得每个条形的具体数值一目了然。
- x:x轴的数据,这里是
-
iplot:这是一个 Plotly 函数,用于在 Jupyter Notebook 或类似环境中显示交互式图表。它会渲染出一个可以通过鼠标悬停、缩放、拖动等操作交互的图表。
使用这种方式生成的交互式图表不仅能够提供静态的数据视图,还允许用户通过交互操作来更深入地探索数据。这种图表非常适合于演示或需要动态交互式数据展示的场合。
销售占比扇形图
iplot(px.pie(names=sales_per_store.index, values=sales_per_store.values,
title='Number of sales for each store'))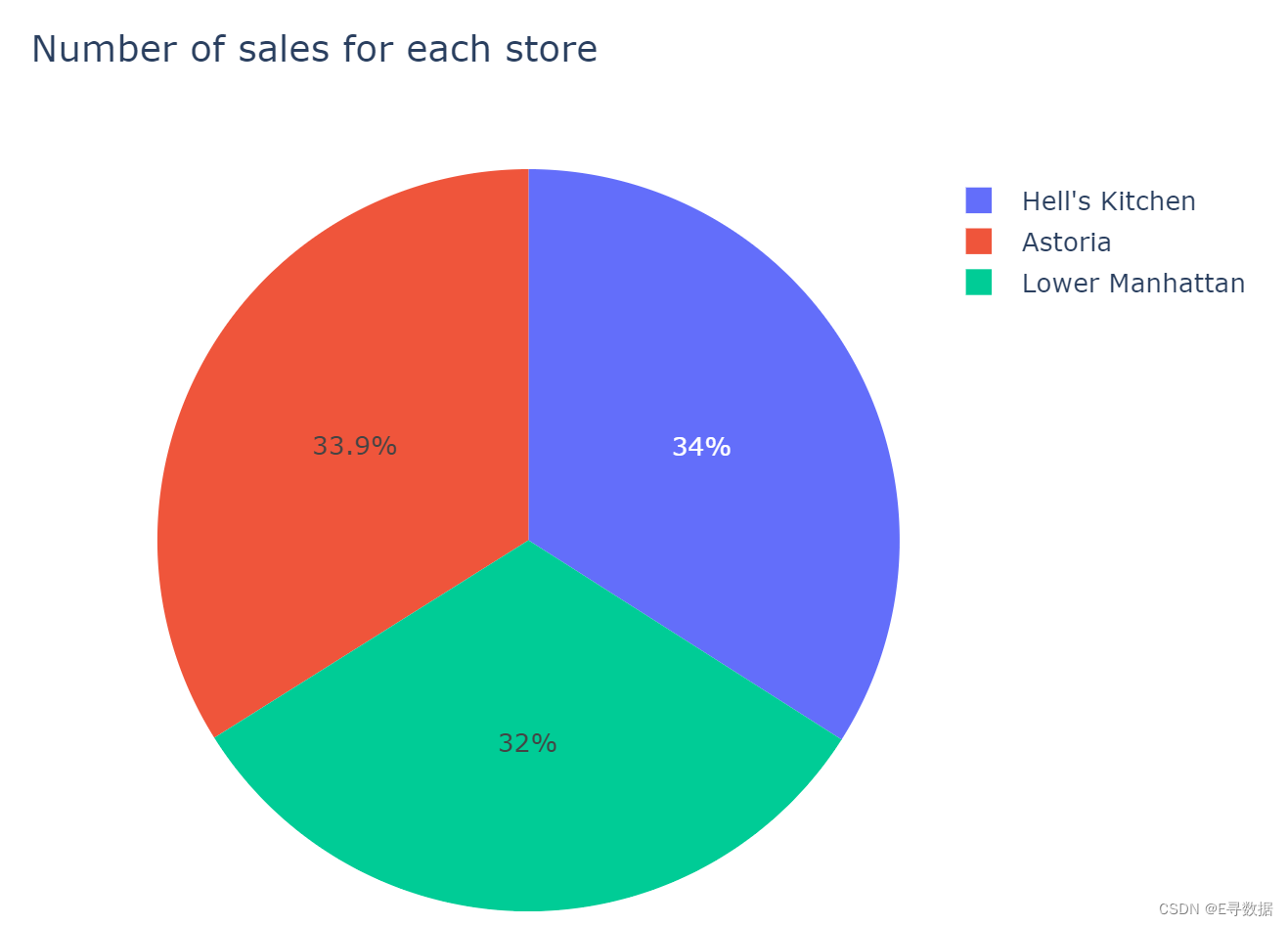
-
px.pie:这是 Plotly Express 中用于生成饼图的函数,它接受以下参数:
- names:这个参数代表饼图中每个扇区的名字,通常对应于数据的分类标签,在这里是
sales_per_store.index,表示每个商店的标识。 - values:这个参数代表与
names对应的数值,即每个分类的大小,在这里是sales_per_store.values,表示每个商店的销售数量。 - title:图表的标题,这里设置为 'Number of sales for each store'(每个商店的销售数量)。
- names:这个参数代表饼图中每个扇区的名字,通常对应于数据的分类标签,在这里是
-
iplot:这个函数用于在 Jupyter Notebook 或类似环境中显示 Plotly 生成的交互式图表。用户可以通过点击不同的扇区来查看详细的数值信息,还可以通过图表下方的工具栏进行放大、缩小、旋转等操作。
价格箱线图
# see 5 number summary to check outliers
sns.boxplot(y = "unit_price", data = df)
- y="unit_price":指定箱线图的数据源,这里使用
unit_price列。y参数表示箱线图的数值是垂直显示的。 - data=df:指定数据框架,即包含
unit_price数据的 DataFrame。
执行这行代码将绘制 unit_price 的箱线图,图中会显示以下几个关键数据点:
- 最小值(Minimum):箱形图下边界之下的线段末端。
- 第一四分位数(Q1, 25th Percentile):箱形的下边界。
- 中位数(Median, 50th Percentile):箱形图中间的线。
- 第三四分位数(Q3, 75th Percentile):箱形的上边界。
- 最大值(Maximum):箱形图上边界之上的线段末端。
- 异常值(Outliers):用小点表示,这些点表示那些远离四分位数范围的数据点。
这个图非常有助于识别可能的数据输入错误或异常数据,可以为进一步的数据清洗和分析提供指导。在商业分析和数据分析的上下文中,识别和处理异常值是非常重要的,因为它们可能扭曲分析结果,导致错误的商业决策。
# see distribution
sns.kdeplot(x = df["unit_price"], fill = True)
plt.show()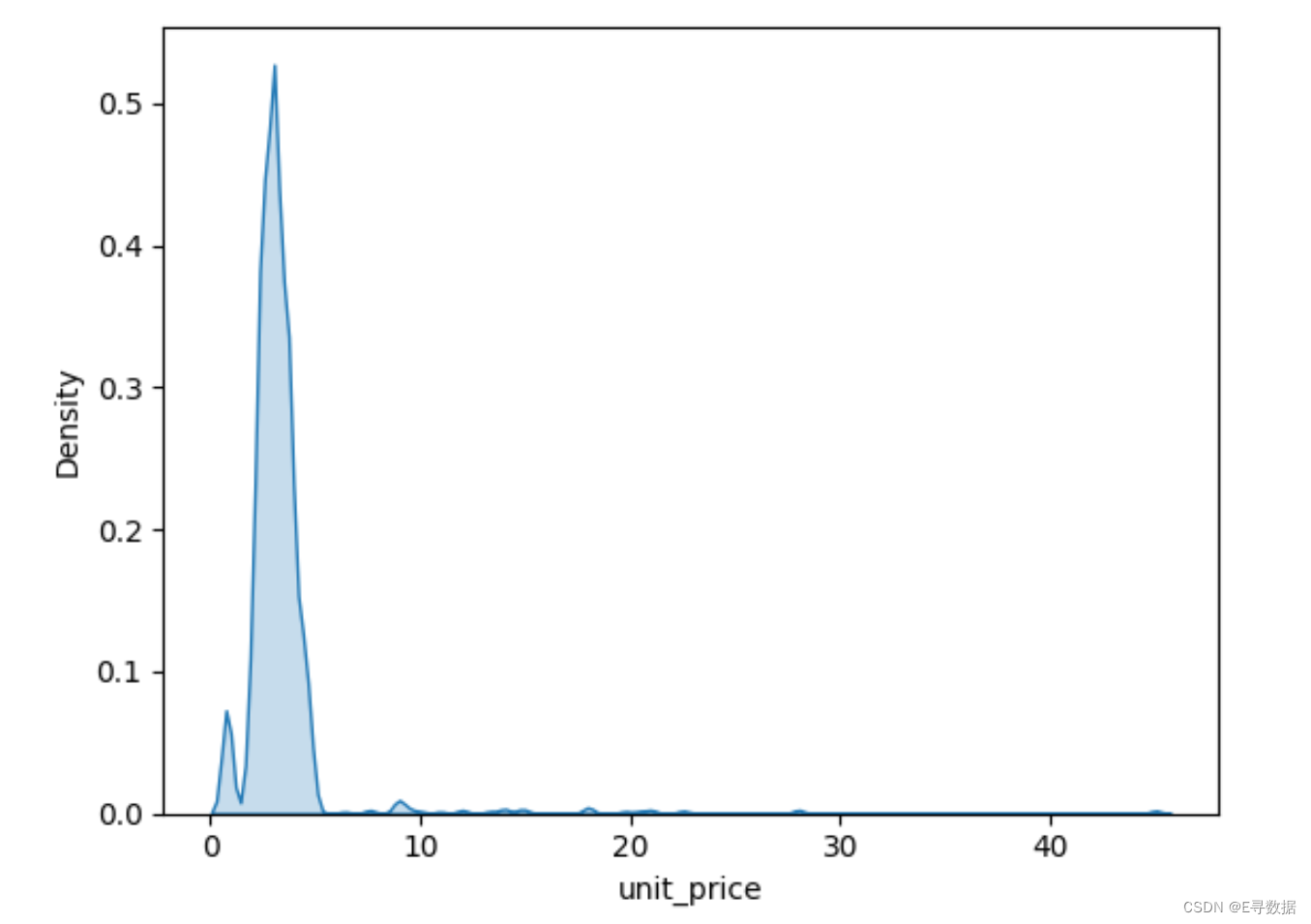
这段代码使用 Seaborn 的 sns.kdeplot 函数来绘制 unit_price 列的核密度估计(KDE)图,这是一种用于展示变量分布的平滑图形方法。以下是代码的详细解释:
-
sns.kdeplot:该函数用于生成一个核密度估计图,这是一种分析单变量分布的方法,它使用核技术平滑地估计概率密度函数。
- x = df["unit_price"]:指定 x 轴的数据源为
df数据框中的unit_price列。 - fill = True:设置
fill=True参数将会填充曲线下的区域,使得密度图的视觉效果更加明显和易于理解。
- x = df["unit_price"]:指定 x 轴的数据源为
-
plt.show():调用这个函数来显示图形。在使用 Matplotlib 和 Seaborn 绘图时,这个函数用来确保所有的绘图命令被渲染,并且显示一个干净的图形,没有额外的文本或信息。
各类别多维度条形图统计
# Assuming 'counts' is the DataFrame obtained from your groupby operation
counts = df.groupby(["product_category", "product_type"]).size().reset_index(name = "count")
# Get unique categories
categories = counts['product_category'].unique()
# Create subplots for each category in a 4x2 grid
fig, axes = plt.subplots(5, 2, figsize = (15, 20))
# Flatten the axes for easier iteration
axes = axes.flatten()
for i, category in enumerate(categories):
# Filter data for each category
subset = counts[counts['product_category'] == category]
# Sort the data by 'count' column in descending order
subset = subset.sort_values('count', ascending = False)
# Create a bar plot for each category with sorted order
sns.barplot(x = 'count', y = 'product_type', data = subset, ax = axes[i], order = subset['product_type'])
axes[i].set_title(f'Product Types in {category}')
axes[i].set_ylabel('')
axes[i].set_xlabel('')
axes[i].tick_params(axis = 'x', rotation = 45)
axes[i].grid(True)
# Adding bar labels
for idx, bar in enumerate(axes[i].patches):
axes[i].text(bar.get_width(), bar.get_y() + bar.get_height() / 2, subset.iloc[idx]['count'], ha = 'left', va = 'center')
# Hide extra subplots if there are fewer categories than subplots
for j in range(len(categories), len(axes)):
axes[j].axis('off')
plt.tight_layout()
plt.show()这段代码非常适合用于在较大的数据集中可视化不同产品类别中各产品类型的数量。它使用了 matplotlib 和 seaborn 库来创建多个条形图,每个图代表一个产品类别。以下是详细步骤的解释:
-
数据准备:
counts = df.groupby(["product_category", "product_type"]).size().reset_index(name = "count"):首先通过对product_category和product_type进行分组,并使用size()方法统计每组的大小,然后调用reset_index()来将分组键转换成列,并将计数结果命名为"count"。
-
获取唯一的产品类别:
categories = counts['product_category'].unique():提取所有独特的产品类别,为后续的循环创建图表做准备。
-
创建多个子图:
fig, axes = plt.subplots(5, 2, figsize = (15, 20)):创建一个 5x2 的子图网格,每个网格用于绘制一个产品类别的条形图,设置整个图形的大小为 15x20 英寸。
-
循环绘图:
- 循环遍历每一个产品类别,并在每个子图中创建一个针对该类别的条形图。
subset = counts[counts['product_category'] == category]:筛选出当前类别的数据。subset = subset.sort_values('count', ascending = False):按照count列降序排序,以便最常见的产品类型最先显示。sns.barplot(x = 'count', y = 'product_type', data = subset, ax = axes[i], order = subset['product_type']):使用 seaborn 的 barplot 绘制每个产品类型的数量,确保条形图按数量排序。- 设置标题、去除 y 轴和 x 轴的标签,并调整 x 轴标签的角度为 45 度以增加可读性。
- 在每个条形图上添加数值标签,显示每个产品类型的具体数量。
-
隐藏多余的子图:
- 如果产品类别的数量少于子图的数量(在本例中为10个子图),则隐藏多余的子图。
-
显示最终结果:
- 使用
plt.tight_layout()优化子图的布局,避免标签或标题重叠。 plt.show()显示最终的图形。
- 使用
商店位置交易量折线图
# stores Vs transaction quantities
# Calculate sum of transaction quantities for each store_location
sum_transaction_qty = df.groupby("store_location")["transaction_qty"].sum().reset_index()
# Create a Plotly line plot
iplot(px.line(sum_transaction_qty, x="store_location", y="transaction_qty",
title="Total Transaction Quantities per Store Location",
labels={"store_location": "Store Location", "transaction_qty": "Total Transaction Quantity"}))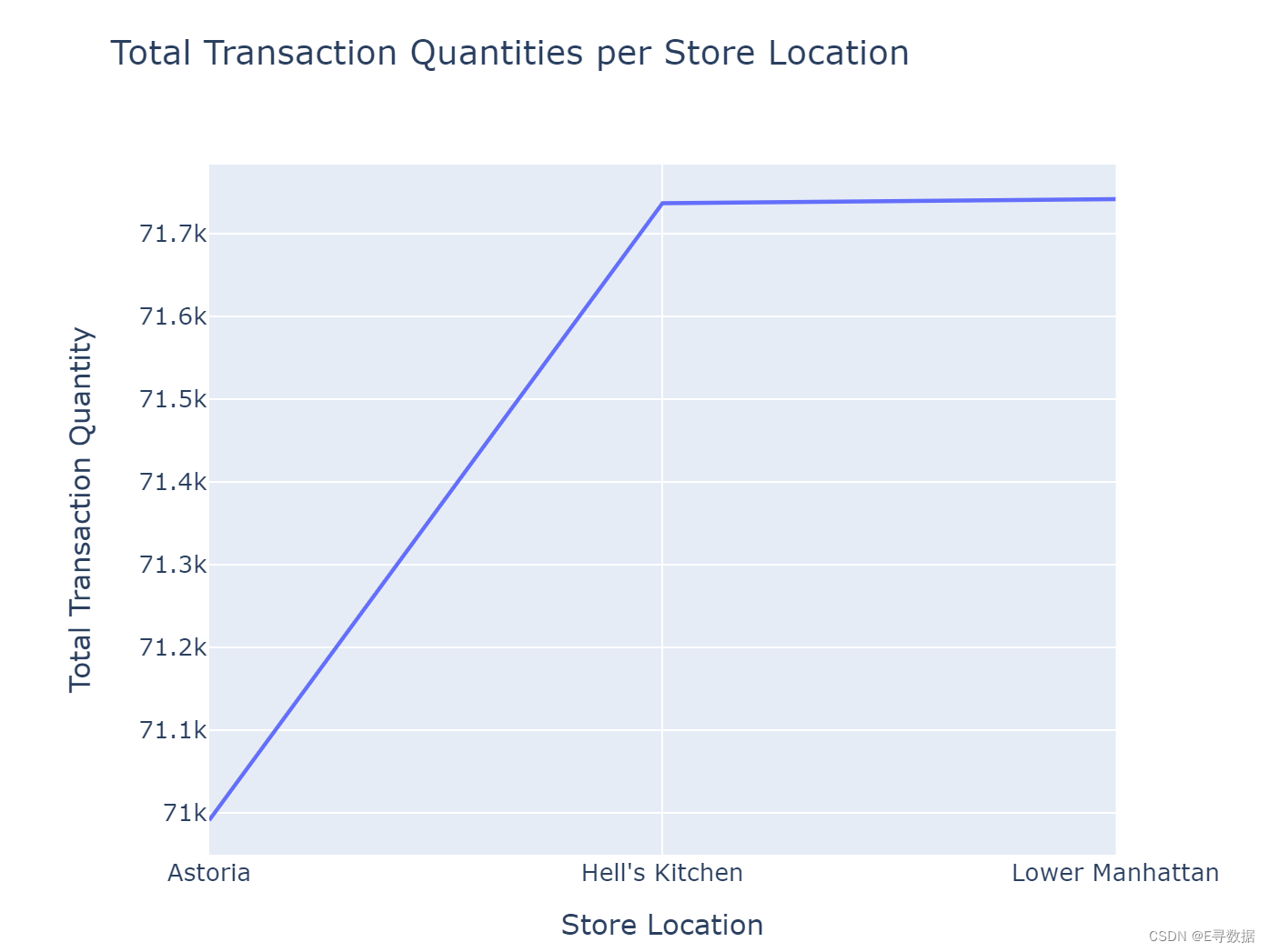
这段代码利用 Plotly Express 创建了一个线性图表,用来展示每个商店位置的交易数量总和。下面是代码的具体解释和步骤:
-
计算每个商店位置的交易数量总和:
sum_transaction_qty = df.groupby("store_location")["transaction_qty"].sum().reset_index():首先通过groupby方法对store_location分组,并对每个组的transaction_qty进行求和。然后调用reset_index()方法使得store_location成为 DataFrame 的一列,而不是索引,这对后续的绘图很重要。
-
创建 Plotly 线图:
iplot(px.line(sum_transaction_qty, x="store_location", y="transaction_qty", title="Total Transaction Quantities per Store Location", labels={"store_location": "Store Location", "transaction_qty": "Total Transaction Quantity"})):使用 Plotly Express 的line函数创建线图。x="store_location":设置 x 轴为商店位置。y="transaction_qty":设置 y 轴为每个位置的交易数量总和。title:图表的标题。labels:定义轴标签的字典,以提高图表的可读性。
不同位置产品受欢迎统计量
# Stores VS product categories
# Calculate number of product categories at each store location
popular_products = df.groupby('store_location')['product_category'].value_counts().reset_index(name='count')
# set figure size
plt.figure(figsize=(10, 5))
# Create a bar plot
sns.barplot(x = 'store_location', y = 'count', hue = 'product_category', data = popular_products, palette = "RdBu")
plt.tight_layout()
plt.show()
这段代码用于绘制一个条形图,显示不同商店位置下各个产品类别的数量。通过这种方式,你可以很容易地识别出在每个店铺中哪些产品类别更受欢迎。以下是具体代码解释和步骤:
-
数据准备:
popular_products = df.groupby('store_location')['product_category'].value_counts().reset_index(name='count'):这一行代码首先对store_location和product_category进行分组,并计算每个商店位置下每个产品类别的数量。使用value_counts()生成计数,然后通过reset_index()将结果转换成一个更易于操作的 DataFrame,并将计数列命名为'count'。
-
设置图形尺寸:
plt.figure(figsize=(10, 5)):设置图形的尺寸为 10x5 英寸,以确保所有的数据都能被清楚地展示。
-
创建条形图:
sns.barplot(x = 'store_location', y = 'count', hue = 'product_category', data = popular_products, palette = "RdBu"):使用 seaborn 的barplot来绘制条形图。x='store_location':指定 x 轴为store_location,即商店位置。y='count':指定 y 轴为计数值,即每个产品类别在各商店位置的数量。hue='product_category':hue参数用来表示不同的产品类别,使得每个类别都有不同的颜色,便于区分。palette="RdBu":选择色板为“RdBu”,它提供了从红到蓝的颜色渐变,有助于在视觉上区分不同的产品类别。
-
调整布局并显示图形:
plt.tight_layout():此函数用于自动调整子图参数,确保子图的标题和轴标签不会重叠,整个图形看起来更加整洁。plt.show():显示图形。这个命令在脚本或 Jupyter Notebook 中执行后,会在输出区域渲染图形。
总收入统计
# Month VS revenue
# Grouping by month and summing the revenue
monthly_revenue = df.groupby("month")["Total revenue"].sum().reset_index().sort_values(by = "Total revenue")
# create line plot
sns.lineplot(x = "month", y = "Total revenue", data = monthly_revenue , marker = "o")
plt.tight_layout()
plt.show()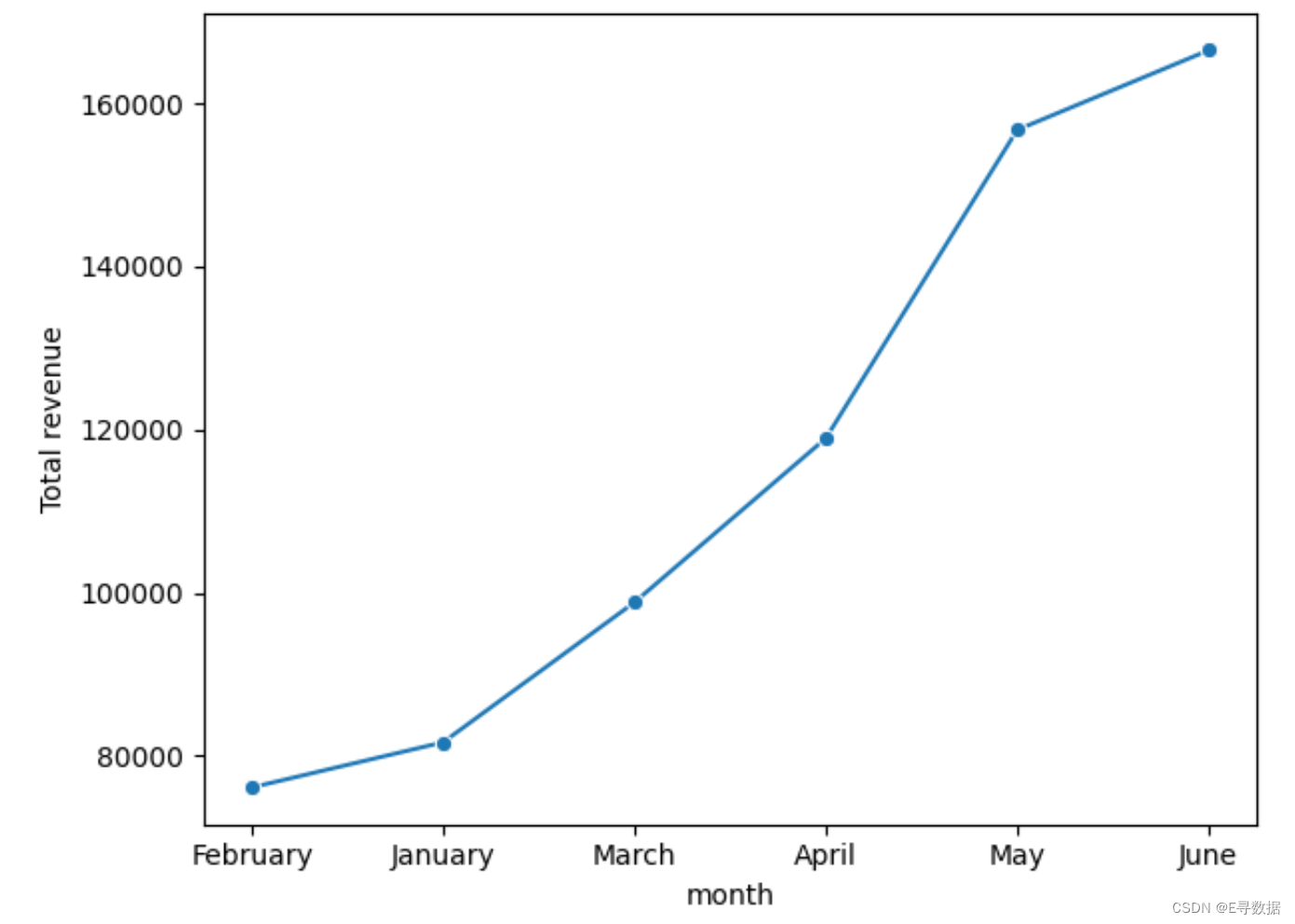
这段代码用于创建一个折线图,展示每个月的总收入情况。折线图是理解时间序列数据,如收入趋势,的一个非常有效的工具。以下是详细的步骤和代码解释:
-
数据聚合:
monthly_revenue = df.groupby("month")["Total revenue"].sum().reset_index().sort_values(by="Total revenue"):首先通过groupby方法按照"month"对数据进行分组,然后对每个组中的"Total revenue"进行求和,得到每个月的总收入。接着使用reset_index()使得month从索引变成列,便于后续操作。最后通过sort_values(by="Total revenue")按照总收入进行排序,确保数据在图表中的顺序是按收入大小排列的。
-
创建折线图:
sns.lineplot(x="month", y="Total revenue", data=monthly_revenue, marker="o"):使用 seaborn 的lineplot函数绘制折线图。x="month":设置 x 轴为"month",表示时间(月份)。y="Total revenue":设置 y 轴为"Total revenue",表示每月的收入总额。data=monthly_revenue:指定数据源为monthly_revenueDataFrame。marker="o":在每个数据点处添加圆形标记("o"),使图表的数据点更加突出,便于观察每个月的具体收入。
-
布局调整和显示图形:
plt.tight_layout():调用此函数以自动调整子图参数,确保图表中的元素(如标签和标题)不会重叠,使图表整体布局更加美观。plt.show():显示最终的图形。这个命令会在 Python 脚本或 Jupyter Notebook 中渲染并展示图形。
总结
本次Kaggle项目中,我们通过一系列详尽的数据分析和可视化手段,深入探讨了咖啡店销售数据。通过处理和分析时间序列数据,我们得以观察到交易数量和销售收入在不同时间维度(如月、日、小时)的分布情况。进一步的数据聚合揭示了各个商店地点和产品类别的流行度,以及每个商店的交易量。此外,我们也评估了产品价格的分布情况,识别潜在的异常值。最终,这些分析为咖啡店的运营管理和策略制定提供了有价值的洞察,帮助业务更好地理解市场动态和顾客偏好。